Our data modules.
We developed a series of modular tools that can be combined with individual models, pipelines, and user interfaces and create custom solutions for our clients.
Ludwig
Language Processing

Text data is a data source available in most organizations. To gain insights from text, we need to structure it and link the information to its context.
Ludwig is our natural language processing approach that combines your domain knowledge with machine-learning extraction algorithms.
We help you structure your domain in a knowledge model and build the pipeline so you can put your text data into action.
Ludwig is named after Ludwig Wittgenstein, an Austrian-British philosopher who worked primarily in logic, the philosophy of mathematics and the philosophy of language.
Ada
Data Pipeline

Data pipelines are at the heart of data-driven organizations. Ada controls the flow of information between a database and a front-end or between databases - making data exchange reliable, scalable and interoperable.
Our pipelines extract valuable data, transform it and distribute it using custom APIs. We design them not only with your current use case in mind but also with possible future scenarios.
The tool's name is a tribute to Ada Lovelace, who published in 1843 the first algorithm explicitly designed for a general-purpose computer. She is often regarded as the first computer programmer.
Florence
Interactive Data Communication
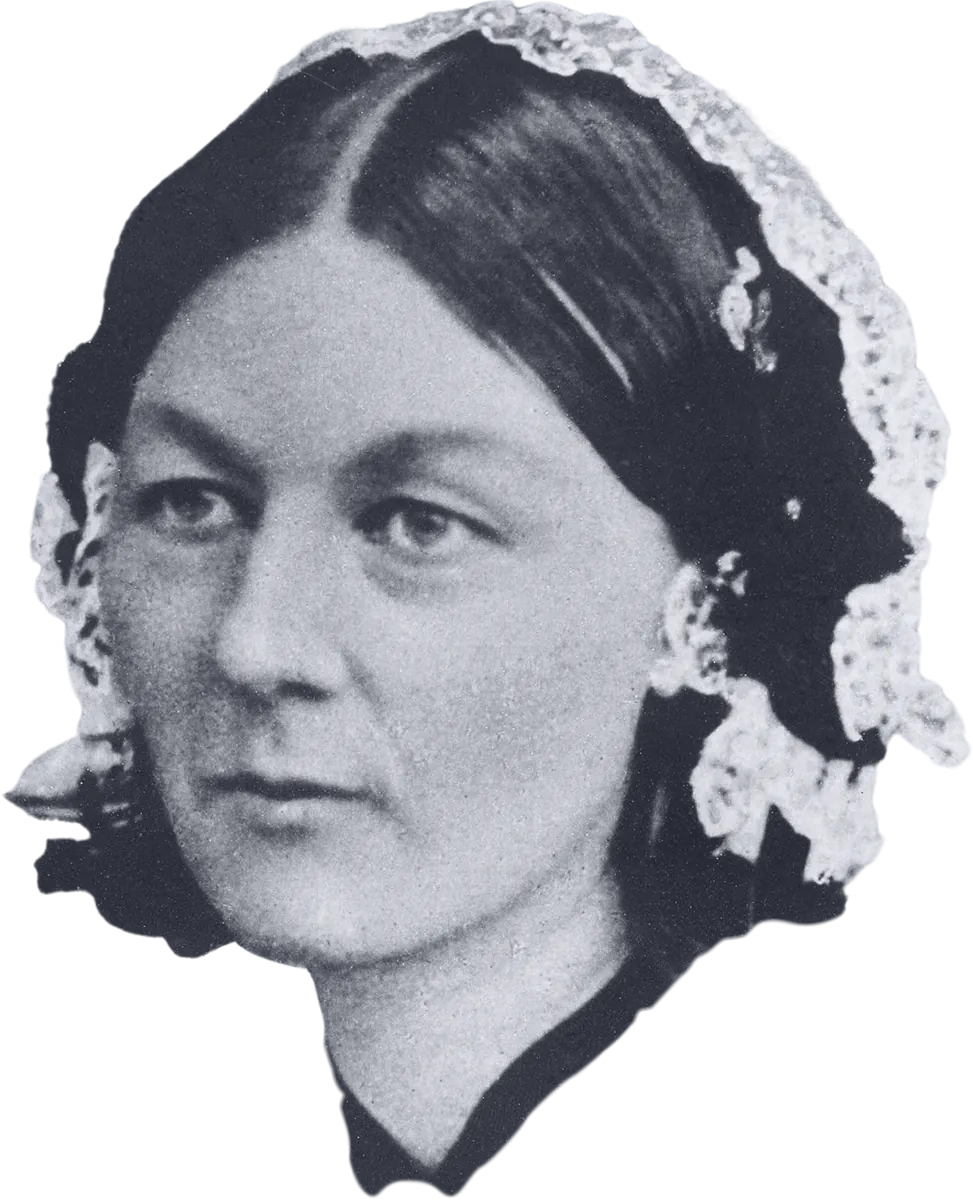
With our dashboard solution, data communication becomes engaging and purposeful. The interface enables the users to find the answers to their questions effortlessly.
We support the development of indicators that matter, choose compelling visualizations and design a unique user experience.
We named the tool after Florence Nightingale, a pioneer in statistics and data visualization.
Gertrude
Survey Data Collection

Our data collection tool allows our clients to design surveys with great flexibility. We help define what insights you want to generate and adapt the user experience to specific contexts.
Gertrude is especially useful for decentralized organizations, for instance, organizations with many subsidiaries or local entities.
The process of sending out the surveys and collecting the results is fully automated and based on a secure user management system.
Gertrude is named after Gertrude Mary Cox, one of the most prominent statisticians of the 20th century.
John
Reporting

Reporting is a fundamental tool for the public and social organizations. With John, it is possible to turn our dashboard and interface solutions into printable reports with one click. The tool allows organizations to publish .pdf reports with ease regularly.
We also support designing the layout, indicators, and infrastructure to build reports with the most recent data automatically.
John Snow, whom we named the tool after, was one of the founders of modern epidemiology. His use of statistics and data visualization was revolutionary in public health.
This website does not use tracking cookies. The only external service we utilize is the Google Maps API to display our office location.
If you prefer not to use Google Maps, you can opt out below. For more details, please refer to our data privacy policy here.
Join the conversation with our Social Data Science Quarterly newsletter.
Our Social Data Science Quarterly newsletter provides an overview of our current work. It is aimed at anyone interested in keeping up with new data solutions, tools, and the latest in social data science, civic tech, and the open-source community.
SUBSCRIBE